|
|
|
|
|
|
We claim that 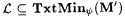 . To see this, suppose T is a text for an . To see this, suppose T is a text for an 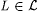 . Then . Then 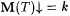 and Wk = L. So, for all sufficiently large n, we have that and Wk = L. So, for all sufficiently large n, we have that 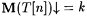 and g(k, n) = iL. Therefore, in the program for M', for all sufficiently large n, the search for (i, j) finds the least (i, j) such that h (i, j) = iL. We consider two cases. and g(k, n) = iL. Therefore, in the program for M', for all sufficiently large n, the search for (i, j) finds the least (i, j) such that h (i, j) = iL. We consider two cases. |
|
|
|
|
|
|
|
|
Case 1: L is finite. In this case it follows from Claim 12.18(a) and our definition of M' that 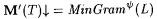 . . |
|
|
|
|
|
|
|
|
Case 2: L is infinite. Suppose 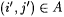 is such that is such that 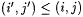 and, for infinitely many n, and, for infinitely many n, 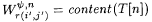 . Then it follows that Wr(i, j) = L. But by Claim 12.18, the only way that can happen is if (i', j') = (i, j). Hence, by the program for M', for all but finitely many n, M'(T[n]) = r(i, j) = MinGram y (L). . Then it follows that Wr(i, j) = L. But by Claim 12.18, the only way that can happen is if (i', j') = (i, j). Hence, by the program for M', for all but finitely many n, M'(T[n]) = r(i, j) = MinGram y (L). |
|
|
|
|
|
|
|
|
It thus follows that 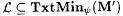 . . |
|
|
|
|
|
|
|
|
§12.6 Nearly Minimal Identification |
|
|
|
|
|
|
|
|
We next consider paradigms in which scientists converge to hypotheses that are of minimal size, modulo a recursive fudge factor. (We say that the hypotheses are of ''nearly minimal" size.) The next two definitions introduce this idea. |
|
|
|
|
|
|
|
|
12.19 Definition Suppose y is a programming system and 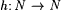 . We say that i is an h-minimal y -grammar for L just in case . We say that i is an h-minimal y -grammar for L just in case 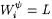 and and 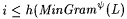 . . |
|
|
|
|
|
|
|
|
12.20 Definition (Case and Chi [27])Suppose 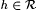 . . |
|
|
|
|
|
|
|
|
(a) M h-TxtMex y -identifies 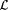 (written: (written: 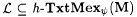 ) just in case, for each ) just in case, for each 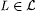 and each text T for L, we have that and each text T for L, we have that 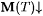 and M(T) is an h-minimal y -grammar for L. and M(T) is an h-minimal y -grammar for L. |
|
|
|
|
|
|
|
|
(b) 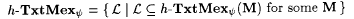 . . |
|
|
|
|
|
|
|
|
(c) 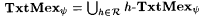 . . |
|
|
|
|
|
|
|
|
The following proposition is immediate. |
|
|
|
|
|
|
|
|
12.21 Proposition For all acceptable programming systems y and y ', TxtMex y = TxtMex Y '. |
|
|
|
|
|
|
|
|
So, if the fudge factor is allowed to be any computable function, the notion of nearly minimal identification is independent of the underlying acceptable programming system. |
|
|
|
|