|
|
|
|
|
|
which case M(x, T) is defined to be this i. If no such i exists, then M(x, T) is said to be undefined. |
|
|
|
|
|
|
|
|
The following two definitions state the text analogs of the Bex and UniBex paradigms. |
|
|
|
|
|
|
|
|
10.18 Definition Let a, 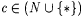 . . |
|
|
|
|
|
|
|
|
(a) M TxtBexa,c-identifies L (written: 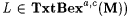 ) just in case, for all ) just in case, for all 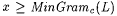 , there is an i with Wi =a L such that, for each text T for L, we have , there is an i with Wi =a L such that, for each text T for L, we have 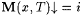 . . |
|
|
|
|
|
|
|
|
(b) 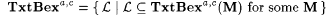 . . |
|
|
|
|
|
|
|
|
10.19 Definition Let a, 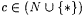 . . |
|
|
|
|
|
|
|
|
(a) M TxtUniBexa,c-identifies L (written: 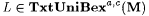 ) just in case there is an i with Wi =a L such that, for each ) just in case there is an i with Wi =a L such that, for each 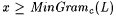 and each text T for L, we have and each text T for L, we have 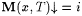 . . |
|
|
|
|
|
|
|
|
(b) 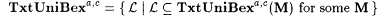 . . |
|
|
|
|
|
|
|
|
Thus, M TxtBexa,c-identifies L just in case M, fed a text for L and an upper bound on MinGramc(L), converges to a grammar that accepts L with at most a errors. As in the case of functions, the reader should note that in the TxtBexa,c paradigms, the scientist may converge to different grammars for different upper bounds. |
|
|
|
|
|
|
|
|
Using the technique demonstrated in Chapter 6 (see, for example, the proof of Proposition 6.19), it is easy to see that the diagonalization results about Bex-identification and UniBex-identification yield analogous results for TxtBex-identification and TxtUniBex-identification. For example, the following result immediately follows from Proposition 10.5. |
|
|
|
|
|
|
|
|
10.20 Proposition For each 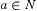 , , 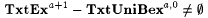 . . |
|
|
|
|
|
|
|
|
10.21 Corollary For each 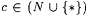 , , 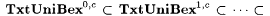 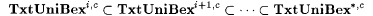 . . |
|
|
|
|
|
|
|
|
The corollary says that by keeping the number of errors in the additional information fixed, larger collections of languages can be TxtUniBex-identified by increasing |
|
|
|
|