|
|
|
|
|
|
8.15 Proposition For all 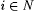 : : |
|
|
|
|
|
|
|
|
(a) 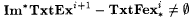 . . |
|
|
|
|
|
|
|
|
(b) 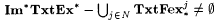 . . |
|
|
|
|
|
|
|
|
(c) 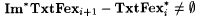 . . |
|
|
|
|
|
|
|
|
(d) 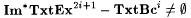 . . |
|
|
|
|
|
|
|
|
(e) 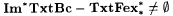 . . |
|
|
|
|
|
|
|
|
(f) 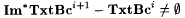 . . |
|
|
|
|
|
|
|
|
The foregoing result yields a collection of hierarchies that are the subject of Exercise 8-16. Some other hierarchies are implied by the following result: |
|
|
|
|
|
|
|
|
8.16 Proposition For each 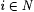 ,. ,. 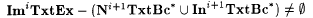 . . |
|
|
|
|
|
|
|
|
Proof: For each finite 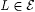 define: define: |
|
|
|
|
|
|
|
|
It is easy to verify that 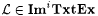 . Also, . Also, 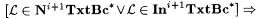 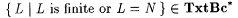 . But, . But, 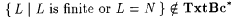 (see Exercise 6-9); thus (see Exercise 6-9); thus 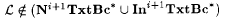 . . |
|
|
|
|
|
|
|
|
§8.1.3 Comparison of Different Kinds of Inaccuracies |
|
|
|
|
|
|
|
|
The last section revealed the extent to which inaccurate data can impede learning. However, no information was provided about the relative impact of different kinds of inaccuracies. For example, which is worse—noise or missing data? In the case of function learning we will see that missing data is strictly more disruptive than noise. To begin, the next proposition shows that there are collections of functions for which programs can be synthesized despite an arbitrary, finite number of noisy points, but for which even finite-variant programs cannot be synthesized if just one datum is missing. The language-identification counterpart of this result follows as an easy corollary. |
|
|
|
|
|
|
|
|
8.17 Proposition 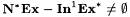 . . |
|
|
|
|