|
|
|
|
|
|
Let untwit be a recursive function such that, for any j -program i, for all x, j untwit(i)(x) = j i(<1, x>). |
|
|
|
|
|
|
|
|
Now, let M'( s ) = untwit(M(twit( s ))). It is easy to see that if M N1Ex*-identifies 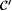 , then M' Ex*-identifies , then M' Ex*-identifies 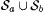 But this yields a contradiction; hence But this yields a contradiction; hence 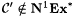 . . |
|
|
|
|
|
|
|
|
Consider the following generalization of collection 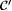 defined in the proof of Proposition 8.12 above. For each defined in the proof of Proposition 8.12 above. For each 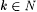 and and 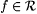 define define 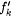 and and 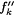 as follows. as follows. |
|
|
|
|
|
|
|
|
Consider also the following collections of functions (where 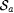 , , 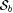 are defined in the proof of Proposition 8.12). are defined in the proof of Proposition 8.12). |
|
|
|
|
|
|
|
|
Using the proof of Proposition 8.12 as a model, it is easy to show that 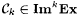 , but , but 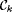 is in neither Nk+1Ex* nor Ink+1Ex* As a straightforward consequence (details are left for the reader), we have the following proposition. is in neither Nk+1Ex* nor Ink+1Ex* As a straightforward consequence (details are left for the reader), we have the following proposition. |
|
|
|
|
|
|
|
|
8.13 Proposition For all 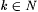 : : |
|
|
|
|
|
|
|
|
(a) 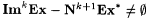 . . |
|
|
|
|
|
|
|
|
(b) 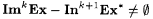 . . |
|
|
|
|
|
|
|
|
Proposition 8.13 yields several corollaries that clarify the relationship between the number of inaccuracies allowed in a text and the ability of scientists to learn on those texts. The following corollary, for example, provides information about Ex-identification from noisy texts. |
|
|
|
|
|
|
|
|
8.14 Corollary 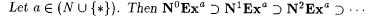 . . |
|
|
|
|
|
|
|
|
Let us now turn our attention to the identification of languages from inaccurate texts. The following Proposition is the language counterpart to Proposition 8.10 and can be shown using techniques similar to those used in Proposition 8.10. We leave the details as an exercise. |
|
|
|
|