|
|
|
|
|
|
Set 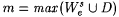 . .
 Enumerate all of ({0, . . . , m} - D) into We. Enumerate all of ({0, . . . , m} - D) into We.
Let s ' be an extension of s s such that content( s ') = ({ 0, . . . , m } - D).
Repeat
Set m = m + 1.
Enumerate m into We.
Set 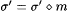 . .
until 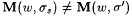 . .
Enumerate all of D into We.
Let s s + 1 be an extension of s ' with content( s s + 1) = [We enumerated until now].
Go to stage s + 1. |
|
|
|
|
|
|
|
|
Now consider the following cases: |
|
|
|
|
|
|
|
|
Case 1: Infinitely many stages halt. In this case, let 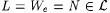 . But, M on text . But, M on text 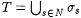 for L with additional information w = max({ e, iN }) fails to converge. for L with additional information w = max({ e, iN }) fails to converge. |
|
|
|
|
|
|
|
|
Case 2: Some stage, s, begins but does not halt. |
|
|
|
|
|
|
|
|
Subcase 2a: The construction never leaves Step 1 in stage s. In this case, let 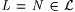 . Note that M on all extensions of s s converges to M(w, s s), and . Note that M on all extensions of s s converges to M(w, s s), and 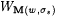 is finite. Thus, M fails to TxtBexa,0-identify N. is finite. Thus, M fails to TxtBexa,0-identify N. |
|
|
|
|
|
|
|
|
Subcase 2b: The construction enters, but never leaves Step 3 in stage s. In this case, let 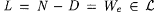 . M on a text for L converges to M(w, s s). But, . M on a text for L converges to M(w, s s). But, 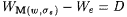 . Thus, . Thus, 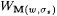 is not an a-variant of L. is not an a-variant of L. |
|
|
|
|
|
|
|
|
From the above cases, it follows that M fails to 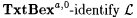 . . |
|
|
|
|
|
|
|
|
The above result has the following corollary that summarizes the advantages of allowing extra errors in the final converged grammar for TxtBex-identification. |
|
|
|
|
|
|
|
|
10.23 CorollaryFor each 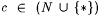 , we have , we have 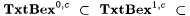 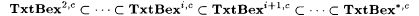 . . |
|
|
|
|
|
|
|
|
The advantage of a better quality of additional information, for both TxtBex-identification and TxtUniBex-identification, is summarized in Corollaries 10.25 and 10.26. These corollaries follow from the next proposition, whose proof is left to Exercise 10-9. |
|
|
|
|
|
|
|
|
10.24 Proposition For each 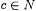 , , 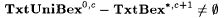 . . |
|
|
|
|