|
|
|
|
|
|
The present section begins to deal with these issues by extending our paradigms to model multiple sources of data, some of which are inaccurate. For this purpose scientists will be conceived as receiving a finite number of texts, announcing hypotheses after examining some initial segment of each of them. To keep the present discussion manageable, we confine ourselves to the identification of functions. |
|
|
|
|
|
|
|
|
To begin, we need to enrich our definition of scientist. |
|
|
|
|
|
|
|
|
8.40 Definition Let 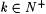 . A scientist with k streams is a computable mapping from SEGIk into N. . A scientist with k streams is a computable mapping from SEGIk into N. |
|
|
|
|
|
|
|
|
8.41 Definition Let 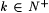 . Fix a k stream scientist M, texts G1,G2, . . . ,Gk, and . Fix a k stream scientist M, texts G1,G2, . . . ,Gk, and 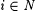 . We say M converges on G1,G2, . . . ,Gk to i (written: . We say M converges on G1,G2, . . . ,Gk to i (written: 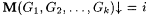 ) just in case there exists an n such that M(G1[n1],G2[n2], . . . , Gk[nk]) = i whenever n1, . . . , nk > n. ) just in case there exists an n such that M(G1[n1],G2[n2], . . . , Gk[nk]) = i whenever n1, . . . , nk > n. |
|
|
|
|
|
|
|
|
Next, we define the identification of functions from multiple texts, some of which could be inaccurate. |
|
|
|
|
|
|
|
|
8.42 Definition Let j 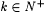 with with 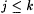 . Let a, . Let a, 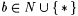 . . |
|
|
|
|
|
|
|
|
(a) M 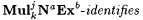 f (written: f (written: 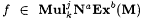 ) just in case for any collection of k texts, G1, G2, . . . , Gk, at least j of which are a-noisy for f, ) just in case for any collection of k texts, G1, G2, . . . , Gk, at least j of which are a-noisy for f, 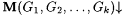 and j M(G1,G2, . . . ,Gk) =b f. and j M(G1,G2, . . . ,Gk) =b f. |
|
|
|
|
|
|
|
|
(b) 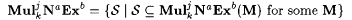 . . |
|
|
|
|
|
|
|
|
(c) 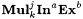 and and 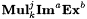 are defined similarly to are defined similarly to 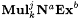 . . |
|
|
|
|
|
|
|
|
8.43 Definition When discussing identification criteria involving multiple data sources, those texts for which the number of inaccuracies is within the bound required by the criteria will be referred to as good texts. |
|
|
|
|
|
|
|
|
The next three propositions describe situations in which learning from multiple inaccurate texts is no more difficult than learning from a single inaccurate text. |
|
|
|
|
|
|
|
|
8.44 Proposition Let j and 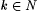 be such that be such that 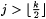 and let and let 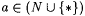 . Then: . Then: |
|
|
|
|
|
|
|
|
(a) 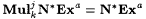 . . |
|
|
|
|
|
|
|
|
(b) 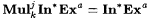 . . |
|
|
|
|
|
|
|
|
(c) 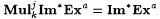 . . |
|
|
|
|