|
|
|
|
|
|
(a) F NonrecLang-identifies L (written: 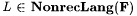 ) just in case for any nonrecursive text T for L, ) just in case for any nonrecursive text T for L, 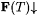 and WF(T) = L. and WF(T) = L. |
|
|
|
|
|
|
|
|
(b) 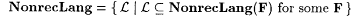 . . |
|
|
|
|
|
|
|
|
(a) M NonrecTxtExa-identifies L (written : 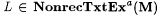 ) just in case for any nonrecursive text T for L, ) just in case for any nonrecursive text T for L, 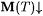 and WM(T) =a L. and WM(T) =a L. |
|
|
|
|
|
|
|
|
(b) 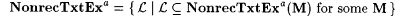 . . |
|
|
|
|
|
|
|
|
It is natural to inquire whether the limitation to nonrecursive texts facilitates identification. The next proposition provides a negative answer to this question for both computable and noncomputable scientists. We omit the proof. |
|
|
|
|
|
|
|
|
(b) (Wiehagen [195]) NonrecTxtEx = TxtEx. |
|
|
|
|
|
|
|
|
The paradigms discussed so far assume that scientists receive data about a given reality from a single source. The source is represented by the single text delivered to a scientist in the course of a single "run." Provided all data are accurate, this model embraces multiple sources of data as well, since a scientist can easily construct a single accurate text by consulting her different sources in some cyclical order. Matters become more complicated if one or more sources are faulty. Consider, for example, a scientist receiving data from multiple sources, some of which produce 1-imperfect text. It is not obvious that she can convert such data into a single 1-imperfect text. |
|
|
|
|
|
|
|
|
This kind of consideration is important to modeling both language acquisition and scientific practice. In the former case it is clear that children are confronted with several sources of linguistic data (in the form of different caretakers, older children, etc.), none of which is 100% grammatically reliable. Similarly, it is common for scientists to base their theories on data collected by different teams working at different places using different instruments, with each team subject to particular forms of error. |
|
|
|
|