|
|
|
|
|
|
For each text G, let the text G' be such that, for all n, x, 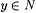 , , |
|
|
|
|
|
|
|
|
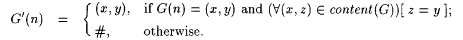 . . |
|
|
|
|
|
|
|
|
Now, if G is an a-noisy text for 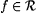 , then G' is an a-incomplete text for f. Moreover, for all but finitely many n, G'[n] = F(G[n]). , then G' is an a-incomplete text for f. Moreover, for all but finitely many n, G'[n] = F(G[n]). |
|
|
|
|
|
|
|
|
For each s , let M'( s ) = M(F( s )). It is easy to see that both 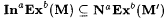 and and 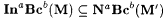 . . |
|
|
|
|
|
|
|
|
The foregoing propositions show that missing data perturb function identification more than noisy data do. In the context of language identification, however, the matter is more subtle. The following proposition, for example, shows that there are collections of languages that can be identified despite one missing datum but cannot be identified in the presence of one noisy datum. |
|
|
|
|
|
|
|
|
8.22 Proposition For each i > 0, 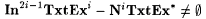 . . |
|
|
|
|
|
|
|
|
Proof: Let 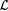 denote the collection of all such denote the collection of all such 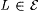 for which there are at least two distinct for which there are at least two distinct 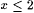 such that colx(L) is nonempty, finite, and such that colx(L) is nonempty, finite, and 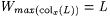 . . |
|
|
|
|
|
|
|
|
We show below, in Lemma 8.23, that 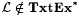 . Using . Using 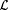 , for each , for each 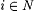 we define we define 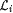 to be the collection of languages to be the collection of languages 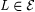 such that for some such that for some 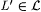 the following hold for all j and x: the following hold for all j and x: |
|
|
|
 |
|
|
|
|
1. 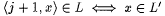 . . |
|
|
|
|
|
|
|
|
2. 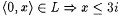 . . |
|
|
|
|
|
|
|
|
3. 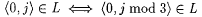 . . |
|
|
|
|
|
|
|
|
4. At least two of <0,0>, <0,1>, and <0,2> are in L. |
|
|
|
|
|
|
|
|
5. If 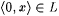 and and 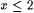 , then colx(L') is nonempty and finite and , then colx(L') is nonempty and finite and 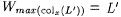 . . |
|
|
|
|
|
|
|
|
We leave it to the reader to show that, for each i, 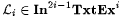 . . |
|
|
|
|
|
|
|
|
Let 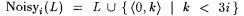 . Clearly, for each . Clearly, for each 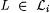 , any text T for Noisyi(L) is also an i-noisy text for L. Lemma 8.23 thus implies that , any text T for Noisyi(L) is also an i-noisy text for L. Lemma 8.23 thus implies that 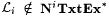 . . |
|
|
|
|
|
|
|
|
8.23 Lemma Let 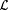 be as deigned in the proof of Proposition 8.22. Then, be as deigned in the proof of Proposition 8.22. Then, 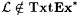 . . |
|
|
|
|