|
|
|
|
|
|
convenient way to denote the data available to scientists from noisy texts. The following definition remedies this. |
|
|
|
|
|
|
|
|
8.4 Definition The set of all finite sequences over N2 is denoted SEGI. By a scientist for identifying functions using imperfect data is meant any computable function (partial or total) from SEGI to N. |
|
|
|
|
|
|
|
|
For brevity in this chapter, we drop the qualifier "for identifying functions using imperfect data" when referring to scientists. |
|
|
|
|
|
|
|
|
8.5 Definition Let 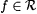 and and 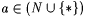 be given. Let G be a text. be given. Let G be a text. |
|
|
|
|
|
|
|
|
(a) G is a-noisy for f just in case 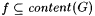 and and 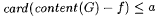 . . |
|
|
|
|
|
|
|
|
(b) G is a-incomplete for f just in case 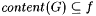 and and 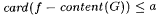 . . |
|
|
|
|
|
|
|
|
(c) G is a-imperfect for f just in case 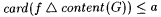 . . |
|
|
|
|
|
|
|
|
Note that two incorrect values for f(n) count as distinct, noisy points. To understand this idea, suppose that G is an inaccurate text for 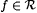 , that f(n) = x, that , that f(n) = x, that 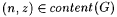 and that x, y, z are all distinct. Then, provided there are no other intrusions, G is a 2-noisy text for f. Further, if we suppress the correct pair (n, x) from the foregoing text G, then it becomes a 3-imperfect text for f. and that x, y, z are all distinct. Then, provided there are no other intrusions, G is a 2-noisy text for f. Further, if we suppress the correct pair (n, x) from the foregoing text G, then it becomes a 3-imperfect text for f. |
|
|
|
|
|
|
|
|
Our task is now to embed the foregoing conceptions of inaccurate data within an associated learning paradigm. One means of achieving this is to require scientists to converge to an accurate index for the target object (language or function), even on texts that harbor inaccuracies. The next definition formalizes this idea for the language case. |
|
|
|
|
|
|
|
|
8.6 Definition Let a, 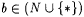 and scientist M be given. and scientist M be given. |
|
|
|
|
|
|
|
|
(a.1) M NaTxtExb-identifies 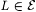 (written: (written: 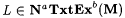 ) just in case for all a-noisy texts T for L, ) just in case for all a-noisy texts T for L, 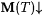 and WM(T) =b L. and WM(T) =b L. |
|
|
|
|
|
|
|
|
(a.2) 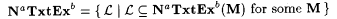 . . |
|
|
|
|
|
|
|
|
(b.1) M InaTxtExb-identifies L (written: 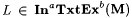 ) just in case for all a-incomplete texts T for L, ) just in case for all a-incomplete texts T for L, 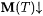 and WM(T) =b L. and WM(T) =b L. |
|
|
|
|
|
|
|
|
(b.2)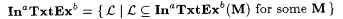 . . |
|
|
|
|
|
|
|
|
(c.1) M ImaTxtExb-identifies L (written: 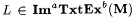 ) just in case ) just in case |
|
|
|
|
|
|
|
|
for all a-imperfect texts T for L, 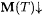 and WM(T) =b L. and WM(T) =b L. |
|
|
|
|