|
|
|
|
|
|
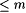 than the number of times p has been output by M on initial segments of f[m]. We leave the details of the proof to the reader. than the number of times p has been output by M on initial segments of f[m]. We leave the details of the proof to the reader. |
|
|
|
|
|
|
|
|
§6.2 Criteria of Language Identification |
|
|
|
|
|
|
|
|
Here we consider generalizations of the TxtEx criterion of language learning that parallel the generalizations of Ex in the previous section. We begin by allowing a finite number of errors into the scientist's final hypothesis. |
|
|
|
|
|
|
|
|
§6.2.1 Anomalous TxtEx-identification |
|
|
|
|
|
|
|
|
Terminology: Recall from Chapter 2 that L1 =n L2 means that 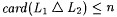 and such L1 and L2 arc called n-variants. Also recall that L1 =* L2 means that and such L1 and L2 arc called n-variants. Also recall that L1 =* L2 means that 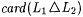 is finite, and such L1 and L2 are called finite-variants. For each is finite, and such L1 and L2 are called finite-variants. For each 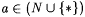 and each L1 and L2 with L1 =a L2, we refer to an index i for L1 as an a-error index for L2. If and each L1 and L2 with L1 =a L2, we refer to an index i for L1 as an a-error index for L2. If 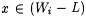 , then we refer to x as an error of commission with respect to i and L. Similarly, , then we refer to x as an error of commission with respect to i and L. Similarly, 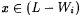 is an error of omission. is an error of omission. |
|
|
|
|
|
|
|
|
We now liberalize TxtEx to allow for a finite number of such errors. |
|
|
|
|
|
|
|
|
6.18 Definition (Osherson and Weinstein [143], Case and Lynes [33]) Let 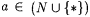 |
|
|
|
|
|
|
|
|
(a) M TxtExa-identifies L just in case for each text T for L, 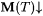 and WM(T) = a L. and WM(T) = a L. |
|
|
|
|
|
|
|
|
(b) M TxtExa-identifies 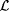 just in case M TxtExa-identifies each just in case M TxtExa-identifies each 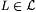 |
|
|
|
|
|
|
|
|
(c) 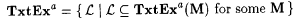 . . |
|
|
|
|
|
|
|
|
The definition implies that  . To show that the hierarchy is in fact strict we rely on a technique that will repeatedly appear in the sequel. It consists of translating results about function identification to the language setting. In the present case Proposition 6.5 and Corollary 6.6 are used to prove the following. . To show that the hierarchy is in fact strict we rely on a technique that will repeatedly appear in the sequel. It consists of translating results about function identification to the language setting. In the present case Proposition 6.5 and Corollary 6.6 are used to prove the following. |
|
|
|
|
|
|
|
|
6.19 Proposition (Case and Lynes [33]) |
|
|
|
|
|
|
|
|
(a) 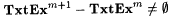 |
|
|
|
|
|
|
|
|
(b) 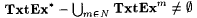 |
|
|
|
|