Morphology
We have been adopting a very neutral stance toward the syntax-morphology interface. Our lexica1 consist not only of lexical items (i.e. lexemes with associated feature bundles), but also of what I have been calling ‘morphological equations’ that specify how to pronounce complex heads.
Some examples of morphological equations are as follows:
- \(\textit{been} = \textsf{PERF}\oplus\textsf{be}\)
- \(\textit{eaten} = \textsf{PASS}\oplus\textsf{eat}\)
- \(\textit{eaten} = \textsf{PERF}\oplus\neg\textsf{PROG}\oplus\textsf{v}\oplus\textsf{ACT}\oplus\textsf{eat}\)
These equations link pronounced forms (on the left) to sequences of lexical items (on the right). For example, the last equation states that the sequence of lexical items \(\textsf{en}\mathrel{::}\underline{\bullet x}.perf\) — \(\epsilon\mathrel{::}\underline{\bullet v}.x\) — \(\epsilon\mathrel{::}\underline{\bullet V}.d\bullet.v\) — \(\epsilon\mathrel{::}\underline{\bullet V_{t}}.k\bullet.V\) — \(\textsf{eat}\mathrel{::}V_{t}\) is pronounced as “eaten.” The original motivation for treating a lexical item as a pair of a sequence of letters (like \(\textsf{eat}\)) and a feature bundle (like \(V_{t}\)) was that the sequence of letters corresponded to the lexical item’s pronunciation. (This is why we have a bunch of ‘silent’ lexical items with the empty sequence of letters.) However, with morphological equations in the picture, we see that the ‘pronounced part’ of a lexical item plays zero role in its pronunciation – lexical items are never pronounced, only sequences thereof are, and this is governed by the morphological equations. It is perhaps better to understand the ‘pronounced part’ of a lexical item as a unique name for that lexical item.
Although these morphological equations have a somewhat mysterious ontological status, it is perfectly clear how they come about from a whole word syntax. When we analyzed a sentence like “John had eaten,” we began with a whole word dependency structure, as in figure 1.
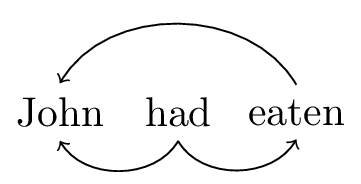
Figure 1: Whole-word dependencies for sentence ‘John had eaten’
This dependency structure is generated by the following set of whole word lexical items, with a trivial set of morphological equations.
| \(\textsf{john}\mathrel{::}d.k\) | \(\textsf{had}\textrm{::}\bullet perf.k\bullet.s\) | \(\textsf{eaten}\textrm{::}\bullet d.perf\) |
| \(\textit{John} = \textsf{john}\) | \(\textit{had} = \textsf{had}\) | \(\textit{eaten} = \textsf{eaten}\) |
Decomposition breaks a single lexical item into two. Decomposing had into an AgrS head and everything else (which I will still call had) can be visualized at the level of the dependency structure, but also makes the morphological equation for had more complex. The heads which have been created through decomposition are colored in figure 2 to indicate their common origin.
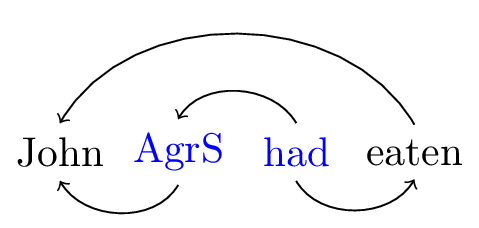
Figure 2: Decomposing had
| \(\textsf{john}\mathrel{::}d.k\) | \(\textsf{had}\textrm{::}\bullet perf.t\) | \(\textsf{eaten}\textrm{::}\bullet d.perf\) |
| \(\textsf{AgrS}\mathrel{::}\underline{\bullet t}.k\bullet.s\) | ||
| \(\textit{John} = \textsf{john}\) | \(\textit{had} = \textsf{AgrS}\oplus\textsf{had}\) | \(\textit{eaten} = \textsf{eaten}\) |
Similarly, we can decompose eaten into a perfective head and verbal stem.
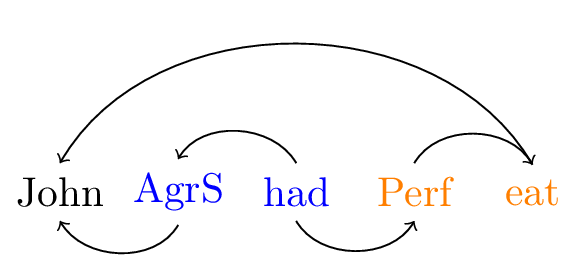
Figure 3: Decomposing eaten
| \(\textsf{john}\mathrel{::}d.k\) | \(\textsf{had}\textrm{::}\bullet x.t\) | \(\textsf{eat}\textrm{::}\bullet d.v\) |
| \(\textsf{AgrS}\mathrel{::}\underline{\bullet t}.k\bullet.s\) | \(\textsf{Perf}\mathrel{::}\underline{\bullet v}.x\) | |
| \(\textit{John} = \textsf{john}\) | \(\textit{had} = \textsf{AgrS}\oplus\textsf{had}\) | \(\textit{eaten} = \textsf{Perf}\oplus\textsf{eat}\) |
As is suggested by this short example, morphological equations begin life as essentially look-up tables, stating that ‘lexical item X is pronounced x.’ As lexical items are syntactically decomposed, these equations simply record the history of the decomposition steps used on lexical items in the grammar.
But what exactly are morphological equations? Are they some new theory of morphology, a rival to DM or PFM? No. They are statements about what a morphological theory, any morphological theory, must do. The equation \(\textit{eaten} = \textsf{Perf}\oplus\neg\textsf{Prog}\oplus\textsf{v}\oplus\textsf{Act}\oplus\textsf{eat}\) is an interface condition, stating that a particular complex of heads must be interpreted by the morphological theory as the word eaten. A particular morphological theory implements the relation between head-complexes and words specified by the set of morphoogical equations. In other words, if we wanted to commit to a theory of morphology, we would use that instead of the word equations.
The morphology-syntax interface
The division of labor presented here between syntax and morphology is that syntax specifies where complex heads are to be pronounced with respect to one another, and morphology realizes complex heads as words. A complex head is determined during the derivation as a sequence of heads where each one (except the last) selects the next using an underlined feature. The spell-out position (but not the morphological form) of this complex head is determined by the strengths of the heads which make it up: following Brody00, it is pronounced as though it were at the position of the highest strong head in the sequence (or in the lowest position, if there are no strong heads).
We can imagine syntax and morphology interacting in the following way. Syntax assembles structures in the way described above (i.e. the way we have been assuming during this course). When it comes time to linearize the structure, syntax gives each complex head to morphology, and places the word morphology outputs in the highest strong position of the underlying complex head. Then we have a structure populated with whole words at various places, which is linearized in the usual way.2
But what exactly is the input to morphology? What are these ‘sequences of heads’? We can visualize these in many equivalent but different looking ways. Here are a few ways of visualizing the complex head referred to by the following morphological equation \(\textit{eaten} = \textsf{Perf}\oplus\neg\textsf{Prog}\oplus\textsf{v}\oplus\textsf{Act}\oplus\textsf{eat}\):
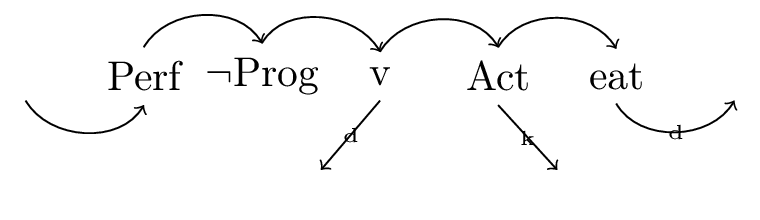
Figure 4: ‘eaten’ as a dependency structure
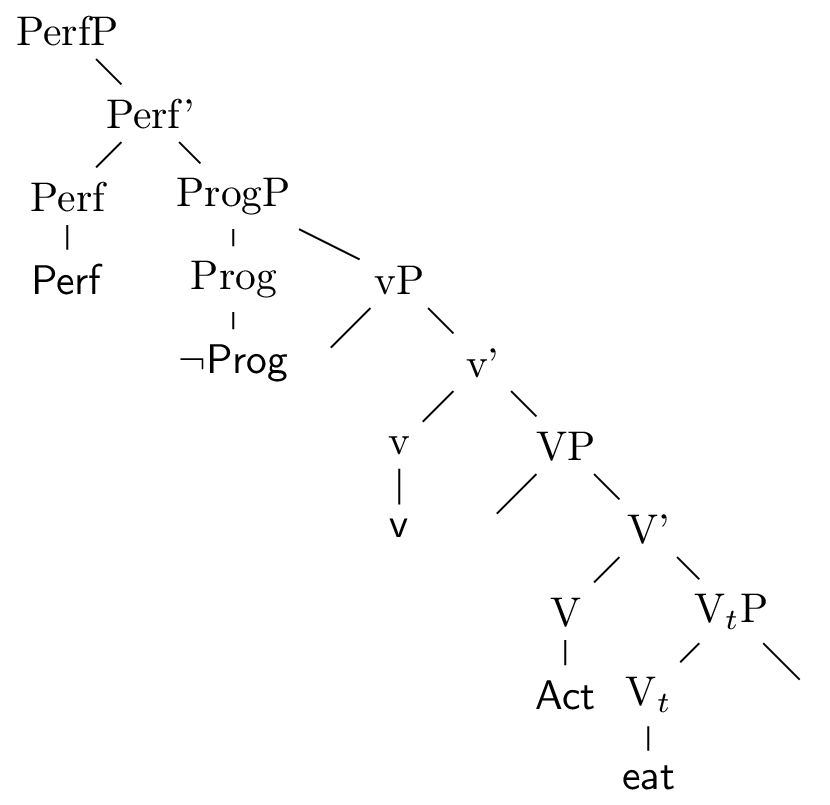
Figure 5: ‘eaten’ as an X-bar structure
Essentially, a complex head is a chunk of structure, possibly with missing constituents. These missing constituents are in the projection of some heads belonging to the complex head, but not themselves part of the complex head. These missing pieces are in the structures above: the deep subject, the deep object, and the object case positions. The reason we need to include these is so as to allow for agreement information to be present in the complex head. In the case of English, there is no morphological sensitivity to these elements, so we don’t really need to include them in these examples. In the chomskyian literature, such a chunk of structure has come to be known as a span Williams03,Svenonius16.
The dependency perspective allows us to view a ‘complex head’ as a smattering of heads, together with their outgoing and incoming arrows. The X-bar representation on the other hand, is far less economical, forcing us to bring along a whole array of X-bars and XPs. A dependency-lite representation has been developed in the X-bar world, which allows one to dispense with much of the additional X-bar and XP nodes - the complex X\(^{0}\). This is shown in figure 6.
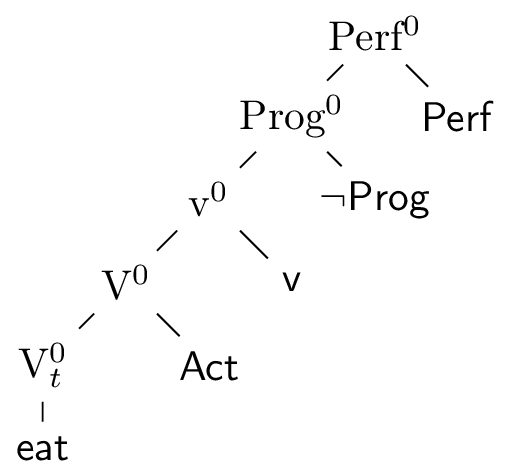
Figure 6: ‘eaten’ as a complex X-bar head
A complex X\(^{0}\) is created by successive head movement. Head movement bundles together complex head formation with complex head positioning in an unfortunate way; to create a complex head, you head move a lower head into a higher one. Thus, if you have created a complex head, it ends up in the position of its highest member. As a strategy for making the XP representation of complex heads smaller, head movement does a passable job. However, the complex X\(^{0}\) representation fails massively at explicitly representing the agreement dependencies of heads - in assembling a complex X\(^{0}\), the heads are divorced from their projections, where the information about their dependencies is present. Thus we need a particular morphological feature based timing implementation of agreement.3
Morphology at work
Morphology must take a complex head as its input, and deliver a word as its output. Stepping back a bit, any morphological theory needs to be able to specify the correct form of a word appropriate for a particular syntactic configuration. At its most basic, a morphological theory must be given a stem, which serves to identify a ‘paradigm’, and inflectional information, which serves to identify a ‘cell’ in that paradigm. This most basic perspective is exemplified by the following complex head (span) for the word has (figure 7 gives the dependency version of this span, and 8 the X-bar version).
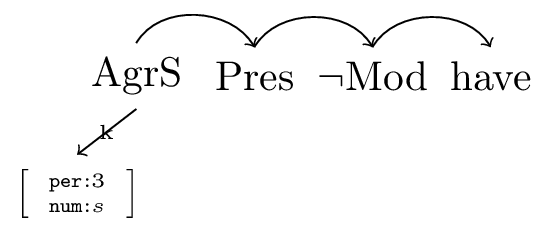
Figure 7: A dependency span for ‘has’
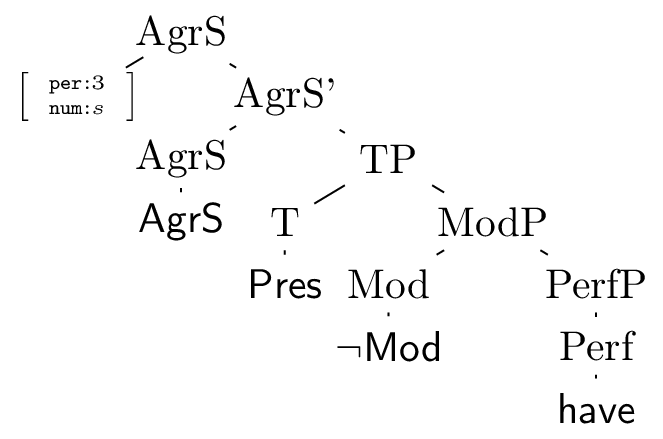
Figure 8: An X-bar span for ‘has’
Both representations of this span contain a stem have, which identifies the paradigm in question, as well as the additional information (that the word is in the present tense, and that the morphologically relevant information about its syntactic environment is that it receives third person singular information from its AgrS specifier) required to identify the cell in that paradigm. Some of the information (that we have not chosen a modal like will or can) is seemingly irrelevant for English morphology, and is only present because of the syntactic analysis. However, what is important is that the morphological module have enough information to do its job.
What kind of morphological theory can make use of this kind of input? All of them. Take distributed morphology. Here we have given DM the usual kind of X-bar structure proponents want to make use of, but where all the irrelevant information (like XPs that don’t belong to the morphological word) has been stripped away. We are free to make use of the array of DM operations (head movement, merger, fission, fusion, etc) on this structure. Note that although this structure was created by the syntax, it is given to the DM morphological module and then from then on anything that happens to it is purely morphology.
Alternatively, consider a word and paradigm model, like paradigm function morphology. In PFM the inputs usually take the form of a pair \(\langle w,\sigma\rangle\), where \(w\) is the stem, and \(\sigma\) the set of inflectional information about the stem. Our spans above don’t obviously have this form. This is deceptive, however, as they in fact do, which is easiest to see from the dependency perspective.
Given the span for has above (figure 7), it is, but for irrelevant information packaging, the same as the pair \(\langle \textsf{have},\{\textsf{AgrS}_{3s},\textsf{Pres},\neg\textsf{Mod}\}\rangle\). More algorithmically, the lowest element of the span corresponds to the stem, and the higher elements (together with any information they might inherit from their dependents) correspond to the elements of the set of inflection information. In other words, PFM will systematically throw away the information about (syntactic) hierarchy that the syntactic span contains.4
-
Recall, the lexicon is the ‘repository of arbitrariness’ - it is where we record the unpredictable information about our languages. ↩︎
-
Please don’t take this hopefully useful intuition, or really any intuition about how grammar works, literally. ↩︎
-
And that concludes my ‘whig history’ of why minimalism looks the way it does. ↩︎
-
This is not quite true - it only holds for inflectional information. Derivational ‘affixes’ must preserve hierarchy information, because this is relevant to the morphology - it matters whether you passivize a causative or causativize a passive. The Mirror principle is the observation that morphological hierarchy generally lines up with syntactic hierarchy. ↩︎