Grammatical function changing operations
Last time we attempted to provide an analysis of the English auxiliary system on methodological first principles. Instead of appealing to theoretical desiderata, such as having a fixed set of functional projections, in a certain order, etc, we began with whole words, and tried systematically to reduce redundancy in our analysis by means of our operation of lexical decomposition. Lexical decomposition is an operation on lexical items which splits one lexical item into two, by dividing its feature bundle into two parts, and giving one part to one, and the other part to the other. We saw that lexical decomposition can sometimes end up decreasing the size of our lexicon, both in terms of the raw number of lexical items used (because parts of lexical items can be reused) but also in terms of the total number of features used.
In this post we will continue with this methodology, looking at more constructions, specifically, adding passivization (and consequently transitive verbs) and raising (both object and subject) to the mix.
Recap and comments from last time
Our final analysis of the English auxiliary system is given below. It differs from the picture we saw at the end of the post last time because I have added a new node (d) and four new edges, corresponding to the DPs John and Mary and the lexical intransitive verbs laugh and cry. In contrast to every thing else in the graph, these correspond to open class lexical items, and so our analysis of the English auxiliary system will grow to account for more sentences by adding more edges exclusively of this kind. The previous graphs just showed the closed class items.

Figure 1: A visualization of our grammar from last time
Our decompositional methodology relies not just on decomposing lexical items, but also on unifying lexical items that seem like they are copies of each other. For example, when decomposing laughs into the root laugh and a tense head s, and cries into the root cry and a tense head s, we made a decision to treat both tense heads as the same. We also decided to treat the tense head resulting from decomposing is into be and s as again the same as this one. This decision was not discussed much, but it was very consequential. Doing this violated the precept of ‘do not change the language by performing decomposition.’ This is because is has a different distribution in the language than laughs - it may be inverted with respect to the subject (as in questions) and it may appear before negation. By unifying the tensed s of is with the tensed s of laughs, we are giving both forms the same derivational future. Once we have made this step, there is no syntactic route back, and so we needed to appeal to some other mechanism to rein in our self-inflicted overgeneration. This took the form of a filter, which blocked certain lexical items from being combined. This filter was characterized as a morphological one, which refused to interpret certain complex heads, but we could just as well have characterized it as a syntactic one, which refused to generate certain complex heads.1 We had a similar overgeneration problem once we introduced do to our language and unified its tense with that of the verbs'. Our filters from last time are shown in figure 1. The unusual descriptions are intended to be predicates of paths through the graph: the predicate lexicalItem holds of a path just in case that path contains that lexical item (i.e. just in case that path goes along an edge representing that lexical item). The paths we want to block are those which do not satisfy both predicates.
| if do then nt or FOC or εQ |
| if lexV then not (nt or Foc or εQ) |
Raising to subject
Our analysis thus far does not generate sentences like the below.
- John will seem to laugh.
- Mary seemed to have been crying.
I assume the following dependencies between whole words.
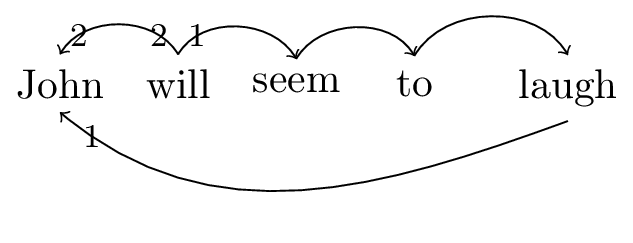
Figure 2: Dependencies for sentence ‘John will seem to laugh
In other words, there is a (selectional) dependency between the embedded verb and the subject, but none between the (uninflected) verb seem and the subject.
In lieu of explicitly decomposing and unifying, I will discuss the process at a high level. The word to in our corpus has the same range of selectional possibilities as does must; it may combine with bare verbs, with have, or with be. It does not combine with will or can. Thus, it must select something of category y. In turn, it itself is not selected by will or can (and so cannot result in something of category y), nor does it inflect (and so cannot result in something of category m), nor can it be affixally negated (and so cannot result in something of category t), focussed (of category pol), nor can it host a subject (and thus cannot be of category foc). For the time being, we will assign it a new category name, i, and allow seem to select something of this category. We arrive at the following new lexical entries.
| \(\textsf{seem}\mathrel{::}\bullet i. v\) | \(\textsf{to}\mathrel{::}\bullet y. i\) |
Our lexicon can be visualized as per the following graph.

Figure 3: Our grammar after raising to subject
One interesting aspect of our new lexicon is that the resulting language is infinite! This can be seen by inspecting the graph, which now contains a cycle; we can go from v to y, and then from y back to v (via lexical items to and seem).
Raising to object
We now consider the following sentences.
- John will expect Mary to laugh.
- Mary believes John to have been crying.
I assume the following dependencies between whole words.
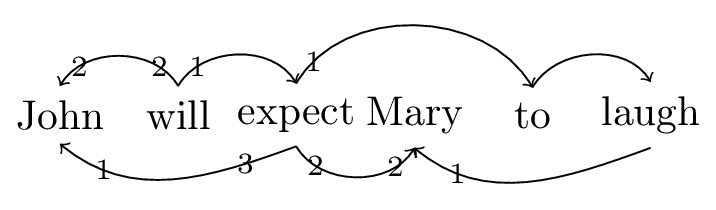
Figure 4: Dependencies for sentence ‘John will expect Mary to laugh’
In other words, there is a (selectional) dependency between the embedded verb and the object, as well as one (a case assignment dependency) between the matrix verb expect and this object. There is also a (selectional) dependency between the matrix verb and the matrix subject.
Based on these dependencies, we initially assign the feature bundle \(\bullet i. k\bullet.d\bullet.v\) to the lexical item expect, allowing it to
- select a non-finite clause (\(\bullet i\))
- check the case of something in this clause (\(k\bullet\))
- select its subject (\(d\bullet\))
- project a vP (\(v\))
Scouring our lexicon, we see that our other (intransitive) verbs contain a similar feature bundle suffix: \(d\bullet.v\). We can decompose our verbs, abstracting out this suffix as a new lexical item: \(\epsilon\mathrel{::}\underline{\bullet V}.d\bullet.v\). We can think of this lexical item as akin to the syntactician’s argument introducing ‘little-v’ head. If object case checking is overt, it is crucial that this new lexical item is strong, as the raising to object verb expect appears before the object, yet the object moves to the specifier of expect when its case is checked. Having this ‘little-v’ head be strong allows expect to head-move to a higher (i.e. lefter) position than the object which moved to its specifier.2 Our lexical verb lexical items now have the following form:
| \(\textsf{laugh}\mathrel{::}V\) | \(\textsf{expect}\mathrel{::}\bullet i.\bullet k. V\) | \(\epsilon\mathrel{::}\underline{\bullet V}.d\bullet.v\) |
Our lexicon can be visualized as per the following graph.

Figure 5: Our grammar after raising to object
For the first time in our graph we have a lexical item (\(\epsilon\mathrel{::}\underline{\bullet V}.d\bullet.v\)) which selects (i.e. externally merges with) two expressions (a big VP and a DP). I have indicated this by having the edge representing this lexical item have two tails: it leaves from the node V and from the node d, and these lines meet up together before continuing to v.
Passivization
Raising to object verbs become raising to subject verbs when passivized.
- Mary is expected to laugh
- John has been being expected to have been crying
I assume the following dependencies between whole words.
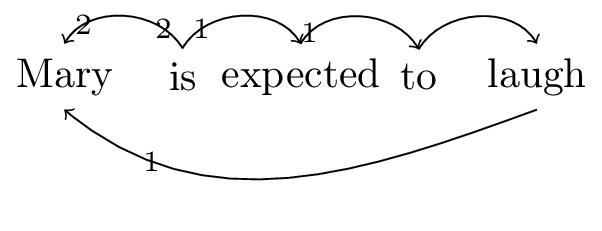
Figure 6: Dependencies for sentence ‘Mary is expected to laugh’
Based on these dependencies, we initially assign the feature bundle \(\bullet i. pass\) to the lexical item expected. We do not want to assign it the same category as seem, because, unlike seem, expected obligatorily combines with a form of be. This be is different from our previous be, as it does not govern the progressive. We assign it the feature bundle \(\bullet pass. v\). We have expect already in our lexicon, with features \(\bullet i.k\bullet.V\). In order to relate our extant expect and new expected, we can decompose out a common core, \(\textsf{expect}\mathrel{::}\bullet i.V_{t}\), and are then left with two ‘residues’: a new ‘passive’ lexical item en, with feature bundle \(\underline{\bullet V_{t}}.pass\), and a new ‘active’ lexical item \(\epsilon\mathrel{::}\underline{\bullet V_{t}}.k\bullet.V\).
Our lexicon can be visualized as per the following graph.

Figure 7: Our grammar after encountering passive raising to object verbs
With this new lexicon, we can immediately analyse transitive verbs (both active and passive):
- John praised Mary.
- Mary will have been criticizing John.
We proceed from the following dependencies (we should talk later about how we get these dependencies).
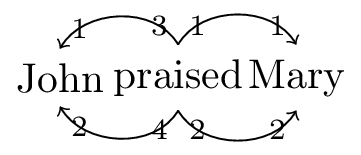
Figure 8: Dependencies for sentence ‘John praised Mary
Based on these dependencies, we can assign the feature bundle \(\bullet d.k\bullet.d\bullet.k\bullet.s\) to praised. Decomposing out pieces that already exist in our lexicon, we are left with the new lexical item \(\textsf{praise}\mathrel{::}\bullet d. V_{t}\).
Our lexicon can be visualized as per the following graph.

Figure 9: Our grammar after encountering transitive verbs
-
One motivation for pushing this to the ‘morphological’ interface is that we are already keeping track of moprhological word-hood when doing decomposition. My intuition is that this provides a plausible story for how a learner could infer this sort of filter from positive data. ↩︎
-
Note that if object case checking is covert, then we cannot account for the word order in sentences with auxiliaries! The raised-to-object subject would surface in its base position adjacent to the lower (!) verb, giving rise to ungrammatical sentences like “John expects to have laughed Mary.” Our initial dependency structure represented a derivation which did not give rise to the correct word order! ↩︎