Agreement and information flow
One way in which our current analysis differs from standard practice in minimalism is that we do not have any operation of agreement. Empirically, given the restricted set of sentences we looked at, this has not been a problem (all of our DPs are third person singular). Once we expand our grammar in an apparently minimal way so as to allow for more variety in DPs, the emprical shortcomings of our analysis manifest.
We begin by considering the following sentences:
- The child is laughing
- The children are laughing
These two sentences have the same gross syntactic dependencies, as depicted below.
Based on these dependencies, we reconstruct the following whole word lexicon.
| \(\textsf{the}\mathrel{::}\bullet n.d.k\) | \(\textsf{children}\mathrel{::}n\) | \(\textsf{are}\mathrel{::}\bullet v.k\bullet.s\) | \(\textsf{laughing}\mathrel{::}\bullet d.v\) |
Decomposing fully, we will find that are is made up of be together with a new lexical item \(\textsf{Prs.PL}\mathrel{::}\underline{\bullet x}.k\bullet.s\). We know, of course, that this lexical item can be decomposed further, but we have not yet seen enough data to force us to do so. On the other hand, we will decompose children (and child) into a nominal root child (or perhaps: CHILD) plus a plural morpheme. We know that the dependency between the and are is a case dependency because we have identified the is in the first sentence with our familiar be plus s (plus AgrS).
| \(\textsf{child}\mathrel{::}N\) | \(\textsf{PL}\mathrel{::}\underline{\bullet N}.n\) | \(\textsf{SG}\mathrel{::}\underline{\bullet N}.n\) | \(\textsf{Prs.PL}\mathrel{::}\underline{\bullet x}.k\bullet.s\) |
| \(\textsf{children} = \textsf{child}\oplus\textsf{PL}\) | \(\textsf{child} = \textsf{child}\oplus\textsf{SG}\) |
Currently, the only verbal forms our grammar allows to be pluralized are are and those of the lexical verbs. This is a generalization beyond the data, which was caused by our decision to ‘find’ our familiar be form in the word are. As there is no categorical distinction between a lexical verb that advances to category \(x\) via an empty lexical item and between a progressive be, our present plural lexical item attaches indiscriminately to both. Encountering more sentences with are pushes us to decompose our present plural morpheme further, both from above and from below.
- The children aren’t laughing.
- The children were laughing.
- The children have laughed.
These sentences show first that \(Prs.PL\) may combine with the negative n’t, and thus that it must deliver to us something of category at highest \(t\), second that the \(Prs.PL\) lexical item should be decomposed into a tense morpheme together with a plural head, and third that have may also combine with a plural head. So, we are in the position of wanting to add a plural (agreement) head somewhere in our inflectional hierarchy. This head should appear somewhere between \(s\) and \(y\). Looking at more data, we can conclude that it must in fact be above \(y\), as it does not occur with to, and above \(m\), as it may occur with do:
- The children are expected to be laughing.
- The children don’t laugh.
It seems, however, as though it might go anywhere! However, we have been neglecting an important distributional fact: the verbal \(PL\) head is inextricably linked to the nominal \(PL\) head.
Agreement
We revisit our analysis, this time explicitly keeping track of agreement. Nodes that agree with one another in the dependency graph will be written in a distinct color.
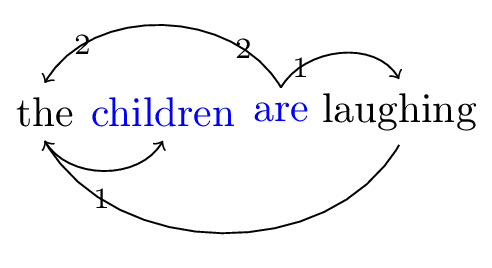
Figure 2: Dependencies for sentence ‘The children are laughing’, with agreement indicated
Our job is now not only to reconstruct the dependencies (and word order) above by assigning feature bundles to lexical items, but also to specify how the similarly colored words ‘come into contact’ with one another. As briefly discussed in a previous post, our language to describe one lexical item coming into contact with another is based on paths in the dependency graph. In the above graph, there are two ways to get from children to are (ignoring directionality of the edges!):
- children – the – laughing – are
- children – the – are
In linguistic terms, the first path proceeds via the merge dependencies between the children and laughing on the one hand, and between laughing and are on the other. The second path proceeds via the move dependency between the children and are.
While the length difference between the two paths is relatively small in this case, when we consider other sentences, we see that choosing to connect children to are via the merge dependency between the children and laughing leads to paths growing without bound. Consider the sentence below.
- The children are expected to have been laughing.
Here the lengths of the paths between child and are begin to diverge greatly:
- children – the – laughing – been – have – to – expected – are
- children – the – are
We see that the direct path between the children and are along the movement dependency is, well, direct. Its length is constant, regardless of the length of the sentence. We will thus adopt this as our working hypothesis about how this agreement is established. This is more of a simplicity-based heuristic, not a knock-down argument; because English is so impovereshed agreement-wise, we would only ever have information from the actual subject passing along any given edge in the graph. (If it had object agreement as well, then certain edges would be ‘overloaded’ if we went along the merge-paths.)
We appeal again to linguistic intuition: the number information on children (and on singular child) is meaningful in a way in which the number information on are (and singular is) is not. The point of this intuition for our analytical purposes is that the number information flow is directed: it flows from children to are (and not the other way around). In order to derive information flow along dependencies from our lexical items, we will need to enrich their feature bundles with information to this effect. A feature \(\overleftarrow{\alpha}\) transmits information to the lexical item which checks it, and a feature \(\overrightarrow{\alpha}\) transmits information from the lexical item which checks it. To transmit information from children to are using the whole-word lexical items introduced in the beginning, we need to modify them as follows:
| \(\textsf{the}\mathrel{::}\overrightarrow{\bullet n.}d.\overleftarrow{k}\) | \(\textsf{children}\mathrel{::}\overleftarrow{n}\) | \(\textsf{are}\mathrel{::}\bullet v.\overrightarrow{k\bullet}.s\) | \(\textsf{laughing}\mathrel{::}\bullet d.v\) |
Decomposing children (and singular child), we obtain the number lexical items \(\textsf{SG}\) and \(\textsf{PL}\), both of which have the feature bundle \(\underline{\bullet N}.\overleftarrow{n}\), meaning, they select a noun root, forming a noun phrase, and upon being selected transmit information to the selecting lexical item. When we decompose are and is, we need to find (or create) a head to which we can transmit number information. The simplest option is to transmit this information directly to the head hosting the \(\bullet k\) feature: the information will flow to (or through) that head anyways. We end up with the single lexical item (an AgrS head) \(\epsilon\mathrel{::}\underline{\bullet v}.\overrightarrow{k\bullet}.s\), which takes information from whatever checks its \(k\bullet\) feature.
Our morphological rules become more complex:
\[\textsf{be}\oplus \textsf{Prs} \oplus AgrS = \left\{\begin{array}{ll} \textsf{is} & \textrm{ if }AgrS\textrm{ is connected to }SG \ \textsf{are}& \textrm{ otherwise}\end{array}\right.\]
The rules look as they do because we are viewing agreement extensionally in terms of heads being connected to other heads, along valid paths. A valid path is one where all of the features involved have arrows pointing in the correct directions (so a feature of the form \(\overleftarrow{\alpha}\) must be checked by one of the form \(\overrightarrow{\beta}\)). This is highly non-standard. It is more standard to view agreement as pushing morphological features around. From this perspective, the head \(PL\) has a morphological feature \([+plural]\), and this feature is being transmitted from head to head along these paths. Ultimately, this feature arrives at the head \(AgrS\), and we can state our morphological rules as follows (where an \(AgrS_{[+plural]}\) is an \(AgrS\) which has a morphological feature \([+plural]\)): \[\textsf{are} = \textsf{be}\oplus \textsf{Prs} \oplus AgrS_{[+plural]}\]
I am happy using this featural notation, but I think it is important to remember that it is simply a way of talking about path information in a (perhaps?) simpler way. In other words, syntax establishes agreement paths, and the morphological form of a word depends on the heads syntax connects it to. How we choose to abbreviate these connections is not an integral part of the present theory.
Homework
Now that we have introduced agreement, we have now an overabundance of ways to make a word like been.
- we can either treat en as a lexical head, directly selected by have, or
- we can treen been as the form be takes, when it is agreed with by have
The first approach is what we have been doing, but the second approach seems more consonant with standard minimalism. Redo the analysis in the post English auxiliaries using the second, agreement based approach! How should we deal with raising to object (or transitive verbs more generally)?