Korpora - Erstellung
Einleitung
Scherer:
- man sollte , „bevor man sich daran macht, ein eigenes Korpus zu erheben, ernsthaft mögliche Alternativen prüfen. Existiert vielleicht ein öffentlich zugängliches Korpus, das für die Untersuchung der Fragestellung geeignet ist?“ (Scherer 2006: 55)
- „Kommt man zu dem Schluss, dass keines der existierenden Korpora für die angestrebte Untersuchung geeignet ist, sollte man überlegen, ob man eines oder mehrere Teilkorpora aus einem bestehenden Korpus nutzen kann.“ (Scherer 2006: 55).
- für bestimmte Varietäten gibt es aber noch immer „keine oder kaum frei zugängliche Korpora“ (Scherer 2006: 55)
- „wenn entsprechende Korpora zugänglich sind, sind diese nicht zwangsläufig für die eigene Untersuchung geeignet.“ (Scherer 2006: 55).
- z. B. bestimmte Korpora des Deutschen sind nicht für eine Untersuchung zum Sprachgebrauch von Frauen und Männern geeignet, weil dort nicht angegeben ist, ob die Texte von Männern oder von Frauen stammen (cf. Scherer 2006: 55).
Möglichkeiten der Korpuserstellung
Lemnitzer und Zinsmeister (2006):
- „das Scannen oder die manuelle Eingabe dürfte nur noch eine geringere Rolle spielen, [d]a mehr als 80% der Texte bereits in der Druckvorstufe digitalisiert sind“ (Lemnitzer / Zinsmeister 2006: 57)
- bei älteren Texten kann es sein, dass man nicht um das Eintippen oder Scannen herumkommt (cf. Lemnitzer / Zinsmeister 2006: 57).
Scherer (2006):
- „Fehlen computerlesbare Textquellen, bleibt schließlich die Möglichkeit, die benötigten Texte einzuscannen und mithilfe eines Texterkennungsprogramms in eine Textdatei umzuwandeln oder die Texte abzutippen.“ (Scherer 2006: 70).
Texterkennungsprogramme arbeiten mit OCR, d. h. mit einer Optical Character Recognition.
Erstellung des Korpus "Italienische Zeitungssprache"
„ein Computereinsatz [war] bei dem Versuch, Varietäten der italienischen Zeitungssprache aufgrund der Realisierungen des Verbalsystems abzugrenzen, nicht von Anfang an beabsichtigt.“ (Burr 1993: 145).
Stattdessen: Die für die Untersuchung ausgewählten Tageszeitungen sollten nach vorher festgelegten Kriterien in Fragmente geteilt, verzettelt und die in Frage kommenden Phänomene manuell ausgezählt werden (cf. Burr 1993: 145).
Frage: ist eine solche Vorgehensweise angesichts der Tatsache, dass es Mittel und Wege gibt, Korpora so zu erstellen, dass sie auf eigentlich unbegrenzte Zeit hinaus und gleichzeitig an verschiedenen Orten für andere Untersuchungen nutzbar gemacht werden konnten, wissenschaftlich wie arbeitsökonomisch noch vertretbar?
Antwort: negativ.
intensive Suche nach verfügbaren und für die Untersuchung geeigneten maschinenlesbaren Korpora.
Anforderungen an das Korpus - Kriterien
Kriterium der Heterogenität: da die Untersuchung der Zeitungssprache und nicht der Sprache einer Zeitung gewidmet sein sollte, konnte das Korpus nicht nur aus einer testata, sondern musste aus mehreren Blättern zugleich bestehen;
Kriterium der diatopischen Streuung: um diatopische Unterschiede in der Zeitungssprache nicht von vorn herein auszuschließen, mussten die einzelnen Blätter aus verschiedenen, darunter auch aus nord- und süditalienischen Regionen stammen;
Kriterium der diastratischen Streuung: d. h. das Korpus sollte nicht nur aus nationalen und / oder Elitezeitungen wie La Repubblica bzw. aus ausgewählten Sparten bestehen, sondern zumindest nominell eine Sprache repräsentieren, die sich aus verschiedenen Sprachniveaus zusammensetzt und somit in Bezug steht zu einer sozio-kulturell heterogenen Leserschaft;
synchronisches Kriterium: Gegenstand der Untersuchung sollte generell ein bestimmter Sprachzustand und nicht die Entwicklung einer bestimmten Sprache sein. Da aber zur Sprechsituation, also zur diaphasischen Dimension, nicht nur die GesprächspartnerInnen und die Umstände des Sprechens gehören, sondern auch das Thema, worüber gesprochen wird, war das synchronische Kriterium sehr eng zu fassen, um so im thematischen Bereich eine relative Homogenität zu erreichen und weiterführende Untersuchungen zur eventuell unterschiedlichen temporalen Darstellung derselben Fakten in den verschiedenen Zeitungen zu ermöglichen;
Kriterium der Exhaustivität: um jegliche Subjektivität aus der Untersuchung auszuschließen, die bei einer a priori Auswahl bestimmter (vermeintlich) neutraler Modalitäten oder spezifischer Stile immer eine Rolle spielt, wurde eine exhaustive Vorgehensweise gewählt und gefordert, dass prinzipiell das gesamte Register Zeitungssprache im Korpus enthalten sein sollte.
Korpora / Datenbanken des Italienischen
Unter den 1990 im Oxford Text Archiv abgelegten fast 1000 Titeln in 20 verschiedenen Sprachen, die zusammen mehr als ein Gigabyte an Textdaten ausmachten, befanden sich gerade einmal 15 italienische Texte klassischer und moderner Autoren. Ein Textkorpus der italienischen Gemeinsprache oder einer ihrer Varietäten fehlte ganz.
Am Istituto di Linguistica Computazionale von Pisa entstand ein Korpus zum Italienischen von 20 Millionen Wortformen. Die Texte wurden direkt vom Verlag Mondadori in schon computerlesbarer Form geliefert und betrafen sowohl literarische als auch Zeitschriftenveröffentlichungen dieses Verlages. Ein relativ kleiner Teil des Korpus sollte auch der Sprache der Tageszeitungen gewidmet sein. Nach mündlicher Auskunft von Mitarbeitern des Instituts war hierbei allerdings nur an La Repubblica gedacht, da sich gerade diese Zeitung im Besitz des Verlages Mondadori befand. Letzterer lieferte aufgrund eines festgelegten Schlüssels regelmäßig Auszüge aus einzelnen Exemplaren der Zeitung. Es handelte sich dabei also nicht um vollständige Ausgaben der Zeitung, sondern um ausgewählte Artikel. Zudem konnte dieses Korpus nur in Pisa selbst benutzt werden, da einerseits der Verlag Rechte daran besaß, andererseits das Korpus entsprechend den in Pisa zur Textbearbeitung entwickelten Programmen aufgestellt wurde und somit nicht unabhängig davon untersucht werden konnte.
Auf der Basis eines maschinenlesbaren Korpus, bestehend aus Texten der Zeitschriften Domenica del Corriere (4 Millionen Wörter), Il Mondo (7,4 Millionen), Europeo (4 Millionen) und der Presseagentur ANSA (10,8 Millionen Wörter) wurde am Centro di Ricerca der IBM in Rom das elektronische Wörterbuch VELI (Vocabolario Elettronico della Lingua Italiana) vor allem für den Bereich der Wirtschaft entwickelt. Auch dieses Korpus war aber nicht frei verfügbar, sondern wurde von der IBM intern für ihre eigenen Forschungen genutzt.
Die Mondadori Gruppe besaß eine eigene Datenbank, in der alle seit dem 1.1.1984 in den dieser Gruppe gehörenden Zeitschriften und in La Repubblica erschienenen Artikel full text und zusammen mit Informationen zu Autor, Art des Artikels, Thematik, genannte Personen, Gesellschaften etc. gespeichert waren. Es handelte sich hierbei um die damals einzige Presseinformationsdatenbank in Italien handelt. Sie wurde fast ausschließlich innerhalb der Verlagsgruppe benutzt, sollte aber später online auf dem Markt verfügbar sein.
Die Wirtschaftszeitung Il Sole 24 ore besaß eine full text Datenbank, diese stand damals aber nur Spezialisten aus der Wirtschaft selbst offen.
Der Verlag La Stampa S.p.A. hatte eine Datenbank aufgebaut, in der zu jedem in La Stampa seit 1982 und in Stampa Sera seit 1983 erschienenen Artikel Informationen wie Erscheinungsdatum, Seitenangabe, Autor des Artikels, Titolatur, Namen der im Artikel genannten Persönlichkeiten, Gesellschaften, Orte, Photographien etc., nicht aber die Texte selbst archiviert wurden, obwohl sie direkt am Terminal und damit digital produziert worden waren. Benutzt wurde diese Datenbank vor allem von den Journalistinnen und Journalisten des Verlags und auch von der RAI (Radiotelevisione Italiana).
Die Möglichkeiten der Korpuserstellung - damals wie heute
Das Sprachmaterial konnte direkt am Bildschirm eingegeben, also abgeschrieben und auf magnetischen Speichermedien abgelegt werden. Diese Art der Textdatenerfassung sollte aber so weit wie möglich ausgeschlossen werden, da sie bei einem umfangreichen Sprachmaterial allgemein und besonders bei kleingedruckten Zeitungstexten viel zu aufwendig schien und davon ausgegangen wurde, dass Ermüdungserscheinungen leicht zu Fehlerquellen führen würden.
Seit einigen Jahren existierten Lesemaschinen, so hießen sie damals, die gedruckte Texte automatisch einlesen konnten.
Bei guten Vorlagen konnte dieses Einlesen nach damaligen Verhältnissen sehr schnell und fast fehlerfrei vor sich gehen. Konkret bedeutete dieses 'fast fehlerfrei', ob es nun 99,5% oder nur 85% ausmachte, dass eingelesene Texte grundsätzlich korrigiert werden mussten.
Auch das immer wieder beschworene interaktiv mögliche Eingreifen in den Leseprozess (cf. z. B. Willée 1989: bes. 122-123) war nur relativ zu den jeweiligen Vorlagen zu sehen. Äußerst nützlich war es besonders dann, wenn zu Beginn der Einlesephase dem Programm das Lesen besonderer Zeichen, Schriftarten etc. sozusagen antrainiert wurde. Ein späteres Eingreifen in den Leseprozess verlangsamt diesen v. a. bei großen Datenmengen dagegen ungemein und stellte zudem keine Garantie für hundertprozentige Fehlerfreiheit dar.
Die italienischen Zeitungstexte bereiteten beim Einlesen allerdings generell sehr große Schwierigkeiten. So hat sich im Laufe der Arbeit schnell gezeigt, dass der einzig gangbare Weg, um brauchbare Einleseergebnisse zu bekommen, das Zerschneiden der einzelnen Zeitungsseiten in ihre Spalten war und die Überschriften vom Einlesen ausgenommen werden mussten. Die Texterkennung von La Repubblica stellte sich aufgrund des unregelmäßigen Drucksatzes als gänzlich unmöglich heraus.
Die bei weitem günstigste Art der Datenbeschaffung bestand in dem Bezug von schon in computerlesbarer Form vorliegendem Sprachmaterial direkt von den Produzenten. Im Falle einer Untersuchung zur Zeitungssprache waren hierfür selbstverständlich die Zeitungsverleger die geeigneten Ansprechpartner. Damals musste aber, wie das Beispiel von La Stampa und La Stampa Sera zeigt, damit gerechnet werden, dass auf Seiten der Zeitungen tatsächlich nicht die Möglichkeit bestand, die Texte bei der Produktion zu archivieren und für Forschungen zur Verfügung zu stellen.
Auswahl der Tageszeitungen
Pragmatische Überlegungen zur Durchführbarkeit der Untersuchung in Relation zum Umfang des Sprachmaterials führten ursprünglich zur Wahl von drei Blättern, nämlich von La Repubblica als nationaler und Elite-Zeitung, des Corriere della Sera als tendenziell nationaler, aber auch lokaler Zeitung einer norditalienischen Region, deren Leserschaft zwar mehrheitlich aus sozio-kulturell hochstehenden Schichten besteht, aber doch breiter gestreut ist, als das bei La Repubblica der Fall ist, und Il Mattino als Vertreterin der Tageszeitungen Süditaliens mit einer lokal und regional ähnlich der des Corriere zusammengesetzten Leserschaft.
Diese drei Blätter sollten im Korpus mit je einer Wochenausgabe vertreten sein, um so zu gewährleisten, dass auch die an den verschiedenen Tagen erscheinenden pagine speciali bzw. inserti berücksichtigt wurden.
Die spätere zusätzliche Aufnahme von La Stampa in das Korpus rechtfertigt sich zum einen dadurch, dass sich diese Zeitung gleich zu Beginn meiner Suche nach maschinenlesbarem Sprachmaterial bereit fand, solches zur Verfügung zu stellen, obwohl dafür erst die Voraussetzungen geschaffen werden mussten. Zum anderen stellte dieses Blatt aufgrund seiner vornehmlich regionalen Verbreitung und Bedeutung eher ein Pendant zu Il Mattino dar, als dies beim Corriere hätte der Fall sein können.
zeitliche Auswahl der Zeitungen / Umsetzung des synchronischen Kriteriums - allein durch den zeitlichen Rahmen, in dem die von La Stampa auf Disketten gelieferten Ausgaben erschienen sind, bestimmt.
La Repubblica: Die negativen Erfahrungen beim Einscannen hatten mich im Laufe der Korpuserstellung dazu gezwungen, diese Zeitung von meiner Untersuchung auszuschließen. Ein erneutes Vorsprechen direkt beim Verleger führte schließlich dazu, dass im letzten Moment doch noch eine Wochenausgabe dieser Zeitung in maschinenlesbarer Form in das Rohkorpus aufgenommen werden konnte.
Erstellung der 4 Teilkorpora - Rohkorpus ca. 2 Millionen Wortformen
a) Corriere della Sera: 16., 17., 18., 19., 20., 21.10.1989
b) Il Mattino: 16., 17., 18., 19., 20., 21.10.1989
Die Wochenausgabe beider Zeitungen lag jeweils in 3 Exemplaren vor und wurde, in Spalten zerschnitten, vollständig mit dem Kurzweil 5000 - Scanner der Universität - Gesamthochschule Duisburg eingelesen. Das sah so aus:
Durch das Scannen gingen auch die äußere Form der einzelnen Texte (Spaltensatz) sowie Hervorhebungen und Kennzeichnungen von 'direkter Rede' und Zitaten vollständig in das Korpus ein. Bei dem anschließenden Korrekturdurchgang am Terminal wurden im Vergleich mit dem gedruckten Exemplar Einlesefehler korrigiert und die Überschriften, die aufgrund entweder ihrer Schriftgröße oder ihres Formats nicht eingelesen werden konnten, hinzugefügt.
d) Stampa Sera: 16.10.1989 und
La Stampa: 17., 18., 19., 20., 21.10.1989
Diese Ausgaben wurde eigens für meine Untersuchung in maschinenlesbarer Form von Luigi Mezzacappa von der Abteilung "Sistemi di Processo" bei La Stampa abgespeichert und mir ebenfalls kostenlos zur Verfügung gestellt.
Als vorerst nicht machbar hatte sich dabei die gleichzeitige Memorisierung der Überschriften erwiesen, die deshalb manuell nachgetragen werden mussten. Die bei der Kontrolle anhand der gedruckten Zeitungsexemplare festgestellten Lücken, die zum einen Agenturmeldungen, Kurznachrichten und die Cronaca di Torino betrafen, zum anderen durch fehlerhafte Dateien bzw. Änderungen redaktioneller Entscheidungen hinsichtlich der Veröffentlichung des einen oder anderen Textes entstanden waren, wurden durch Einlesen oder Abschreiben der entsprechenden Texte behoben.
Artikel, die zwar auf Diskette gespeichert, aber in der gedruckten Ausgabe nicht erschienen waren, sind nicht in das Korpus aufgenommen worden. Auch in diesem Teilkorpus entspricht bisher die Zeilenschaltung nicht durchgängig der gedruckten Form.
c) La Repubblica: 15./16., 17., 18., 19., 20., 21.10.1989
Es handelt sich hierbei um Kopien der in der Datenbank des Verlags Mondadori elektronisch abgespeicherten Zeitungen, die mir zu Forschungszwecken ausnahmsweise und kostenlos zur Verfügung gestellt wurden.
Einzelne in die Datenbank nicht aufgenommene, aber in der Zeitung erschienene Artikel sowie die Kulturbeilage (paginone) wurden am Terminal direkt erfasst.
Während die aus der Datenbank stammenden Artikel die gedruckte Form nicht wiedergaben, und zwar sowohl was die Zeilenschaltung als auch Anführungszeichen zur Indizierung der direkten Rede und Hervorhebungen betrifft, wurde bei den von mir erfassten Texten von Anfang an darauf geachtet, dass alle Informationen, die im gedruckten Text erscheinen, in der elektronischen Form berücksichtigt wurden.
Aus dem Korpus ausgeschlossen wurden:
- alle Tabellen, Listen, Schemata oder Graphen,
- Bildunterschriften, Aufzählungen von sportlichen Wettkämpfen, Börsenquotierungen, Fernseh-, Film- und Theaterprogramme, Veranstaltungskalender, Zug-, Flug- und Schiffsverbindungen, Apothekennotdienste, Nachttankstellen,
- alle Typen von Anzeigen (Stellenangebote, Todesanzeigen etc.) sowie die Anzeigenwerbung,
- die nicht als pagina speciale, sondern als eine spezifische Form der Anzeigenwerbung innerhalb von Sparten auftretende pubblicità redazionale.
In das Korpus aufgenommen wurden dagegen: die sogenannten numeri speciali, "che raggruppano avvisi pubblicitari e testi dedicati a un solo argomento" (Murialdi 121982: 283). Diese in den Zeitungen zumeist als Speciale gekennzeichneten Seiten dienen zwar der Werbung, sind aber nach Murialdi z. T. eine Mischform aus von den Werbeagenturen gelieferten Aufträgen und von den Zeitungsredaktionen erstellten Texten, z. T. werden sie ausschließlich von den Werbeagenturen produziert, fügen sich aber aufgrund ihrer mit den Zeitungstexten identischen Form so in die Zeitung ein, dass ihr Werbecharakter nicht sogleich erkennbar ist.
Erstellung des Korpus "Europawahlen 1994 "
- es gab schon CD-ROMs
- Zeitungsverlage hatten weniger Probleme, Ausgaben in elektronischer Form zur Verfügung zu stellen
- damit waren und sind nicht alle Probleme gelöst
Le Monde:
- erschien seit 1993 auf einer von Research Publications, dann Primary Source Media, vertriebenen CD-ROM.
- 1993 kostete die Gesamtausgabe von 1992 noch 4.850 F HT und die Ausgabe von 1993 5.650 F HT.
- Für die Ausgabe von 1994 gab es einen Schulpreis von ca. DM 450.-
La Vanguardia (in Katalonien auf Spanisch erscheinende Tageszeitung)
- Verlag war bereit, Zeitungsausgaben in elektronischer Form zur Verfügung zu stellen
- elektronische Version sollte entweder insgesamt oder zumindest zum Teil im Quark-Format erscheinen
- QuarkXPress ist ein Desktop-Publishing Programm, das es damals nur für Apple-Computer gab (cf. http://de.wikipedia.org/wiki/QuarkXPress) und überaus teuer war
- ich hatte einen PC
- Disketten: es war unmöglich mit den vorhandenen Mitteln auf die Texte zuzugreifen
- Texte mussten aus ihrer graphischen und drucktechnischen Kodierungsumgebung extrahiert werden
- dafür benötigte Programme waren überaus teuer und liefen nur auf speziellen und sehr teuren Maschinen
Gert-jaan Burggraaf betrieb damals in einem kleinen Ort in den Niederlanden eine Consultancy für Automation und Entwicklung.
- Sein Können wurde von verschiedenen Zeitungsverlagen nicht nur in Europa in Anspruch genommen
- dadurch hatte er Zugang zu den entsprechenden Strukturen
- Beim Telegraph in London hat er während Zeiten des Leerlaufs der maschinengestützten Produktion die elektronische Version der zwei Wochenausgaben von La Vanguardia für einen normalen PC lesbar gemacht
Corriere della Sera
erste CD erschien 1992 = Index der zwischen 1984 und 1991 in der Zeitung publizierten Artikel (Lit. 750.000 ohne MwSt)

Mit Jahresausgabe des Corriere von 1992 auf CD-ROM standen auch die Artikel selbst zur Verfügung
Eingestellt wurde die Produktion von CD-ROMs mit den digitalen Jahresausgaben des Corriere 1998.
CD-ROM Ausgabe des Corriere von 1994 (Lit. 600.000 incl. MwSt.)
Klappentext: " Questo archivio elettronico su CD-ROM (Compact Disc – Read Only Memory) contiene 76.921 articoli pubblicati sul quotidiano e sui supplementi (ad eccezione del supplemento illustrato “Sette”)."
die einzelnen Archive richteten sich an „broker dell’informazione, biblioteche, centri studio e ricerca, centri documentazione, società di consulenza, studi legali, scuole superiori, etc.“
Die Oberfläche des beigegebenen Textretrieval-Programms macht klar, weshalb digitale Texte mit Markup anzureichern sind.
Die Campi können nur dann als Suchkriterien fungieren, wenn die entsprechenden Textstellen selbst vorher als Titolo, Generi etc. ausgezeichnet wurden:

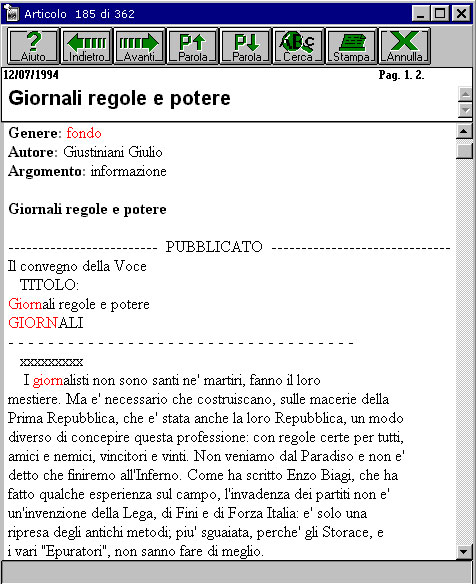
Aufgrund dieses Markup kann nach einzelnen Wortformen entweder nur in den Titeln (Titolo) oder sowohl in den Titel als auch in den Artikeln (Testo) eines bestimmten Genere (elzeviro, fondo etc.) zu einem bestimmten Argomento in einer oder mehreren Ausgaben des Corriere 1994 gesucht werden.
Welche Wortformen (tokens) im Archiv mit welcher Frequenz enthalten sind, erfahre ich übrigens unter dem Menüpunkt A-Z. Das Setzen einer Wildcard ist zugelassen (giorn*):
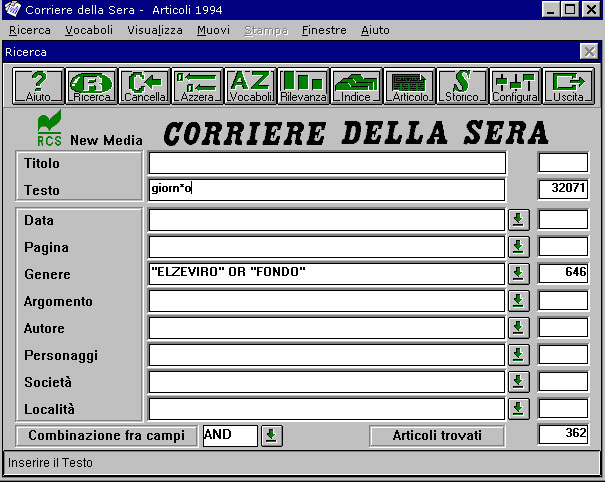
Als Ergebnis wird eine Liste der Artikel ausgeworfen, die den Suchkriterien entsprechen:
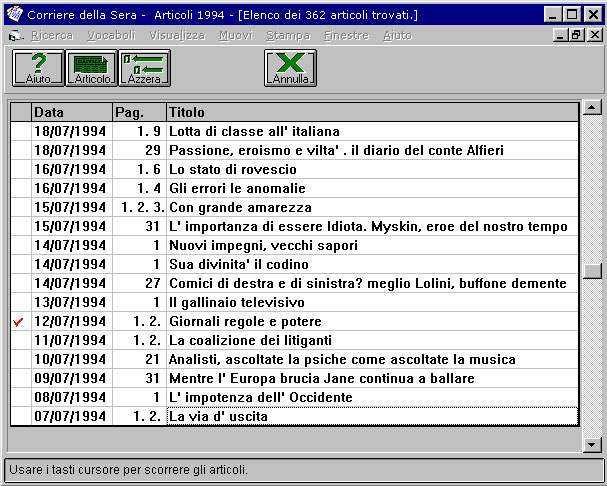
Jeder dieser Artikel kann als Ganzes eingesehen, ausgedruckt oder als Datei abgespeichert werden. Nicht möglich ist allerdings, mehrere Texte gleichzeitig zu exportieren. Soll aus dem Archiv also ein Korpus entstehen, muss jeder der 76.401 Artikel einzeln auf einem Datenträger archiviert werden: