|
|
|
|
|
|
§3.2 Language Identification: Hypotheses, Data |
|
|
|
|
|
|
|
|
Let us now complete the definition of the language identification paradigm. It has already been said that the theoretically possible realities—item 3.1a in our list of concepts—are the members of 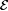 , the collection of all languages. It is thus natural to conceive of "intelligible hypotheses" as computer programs or "grammars" for accepting languages. More precisely, it will prove simpler to assimilate hypotheses to the indexes associated with programs, as explained in Chapter 2. To aid intuition, however, we shall often revert to the terminology of grammars and programs. Items 3.1a,b are thereby specified. , the collection of all languages. It is thus natural to conceive of "intelligible hypotheses" as computer programs or "grammars" for accepting languages. More precisely, it will prove simpler to assimilate hypotheses to the indexes associated with programs, as explained in Chapter 2. To aid intuition, however, we shall often revert to the terminology of grammars and programs. Items 3.1a,b are thereby specified. |
|
|
|
|
|
|
|
|
Turning to 3.1c, we consider the data that Nature makes available about any given language, L. The totality of all such data is conceived as a listing of L in some arbitrary order. To allow such a list to contain pauses in the presentation of data (corresponding to moments in which there is no linguistic input), we adjoin a nonnumerical element # to N. Our conception of 3.1c may then be rendered as follows. |
|
|
|
|
|
|
|
|
3.4 Definition (Gold [80]) |
|
|
|
|
|
|
|
|
(a) A text is any mapping of N into 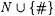 . A text may be visualized as an infinite sequence x0, x1, x2, . . . of members of . A text may be visualized as an infinite sequence x0, x1, x2, . . . of members of 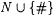 . (The typical variable for texts is T.) . (The typical variable for texts is T.) |
|
|
|
|
|
|
|
|
(b) The set of numbers appearing in a text T is denoted by content(T). (Thus, the content of a text never includes #.) |
|
|
|
|
|
|
|
|
(c) Let 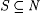 and text T be given. T is for S just in case content(T) = S. and text T be given. T is for S just in case content(T) = S. |
|
|
|
|
|
|
|
|
For example, consider the following text T: |
|
|
|
|
|
|
|
|
3.5 0, 0, #, #, 2, 2, #, #, 4, 4, #, #, 6, 6, . . . |
|
|
|
|
|
|
|
|
content(T) = {0, 2, 4, 6,...}, so T is "for" the set of even numbers. We note that there are uncountably many texts for any nonempty language. On the other hand, there is only one text for 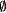 , namely: #, #, #, . . . . , namely: #, #, #, . . . . |
|
|
|
|
|
|
|
|
From the point of view of language acquisition, texts may be understood as follows. We imagine that the sentences of a language are presented to the child in an arbitrary order, repetitions allowed, with no ungrammatical intrusions. Negative information is withheld—that is, ungrammatical strings, so marked, are not presented. Each sentence of the language eventually appears in the available corpus, but no restriction is placed on the order of their arrival. In the event that the language in question is infinite, different sentences continually arise, even though there may also be repetitions of previously presented sentences. If the language is finite, it is possible for the text to finish with an |
|
|
|
|