|
|
|
|
|
|
8.54 Corollary Let a, b, 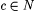 be such that be such that 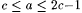 and max and max 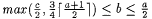 . Then, . Then, 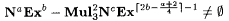 . . |
|
|
|
|
|
|
|
|
Proof: Take 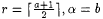 in the above lemma. in the above lemma. |
|
|
|
|
|
|
|
|
The above results show that there are collections of functions for which a program that makes up to d errors can be identified from a single c-noisy text, but for which a program with up to d errors cannot be identified from three texts, at least two of which are c-noisy. Clearly, a price is being paid for distinguishing good texts from "bad" ones. An obvious question is whether this decrease in competence due to learning from multiple texts can be overcome by either decreasing the noise in good texts or by allowing the final inferred program to make extra errors. Some of these questions are treated in the exercises. |
|
|
|
|
|
|
|
|
The first study of inaccuracies is due to Schäfer-Richter [167]. This subject was also treated by Osherson, Stob, and Weinstein [140], Fulk and Jain [74], and Fulk, Jain, and Osherson [75]. The subject of infinite inaccuracies is treated by Jain [83]. An interesting approach to modeling noise in data is due to Stephan [186]. The study of learning from multiple sources of inaccuracies is due to Baliga, Jain, and Sharma [12]. |
|
|
|
|
|
|
|
|
The study of informants was first considered by Gold [80]. The subject of recursive and nonrecursive texts has been investigated by Wiehagen [195] and Freivalds [64]. |
|
|
|
|
|
|
|
|
8-1 For each 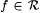 , let f' be such that ( " i, x)[f'(<i, x>) = f(x)]. Suppose , let f' be such that ( " i, x)[f'(<i, x>) = f(x)]. Suppose 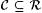 is given. Show that is given. Show that 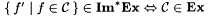 . . |
|
|
|
|
|
|
|
|
8-2 Prove the following. Recall that 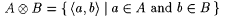 . . |
|
|
|
|
|
|
|
|
(a) Let 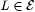 be recursive. Then, be recursive. Then, 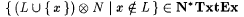 . . |
|
|
|
|
|
|
|
|
(b) 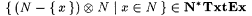 |
|
|
|
|
|
|
|
|
8-3 Consider the notion of identification from *-noisy texts by scientists that need not be computable. Recall that F ranges over any kind of scientists, possibly noncomputable. |
|
|
|
|