|
|
|
|
|
|
By Exercise 8-25 we also have: |
|
|
|
|
|
|
|
|
8.46 Proposition Let j and 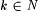 be such that be such that 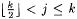 and let and let 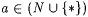 . Then: . Then: |
|
|
|
|
|
|
|
|
(a) 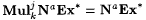 . . |
|
|
|
|
|
|
|
|
(b) 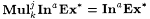 . . |
|
|
|
|
|
|
|
|
(c) 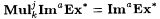 |
|
|
|
|
|
|
|
|
The last three results inform us that if the number of inaccuracies is finite without any preassigned bound, or if the final program witnessing the identification is required to be either accurate or make a finite number of mistakes without any preassigned bound, then learning from multiple texts does no harm so long as a majority of the input texts are good. |
|
|
|
|
|
|
|
|
The next two propositions follow from Propositions 8.45, 8.44, 8.13, and 8.10. |
|
|
|
|
|
|
|
|
8.47 Proposition Let b, j, 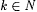 , , 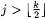 . Then: . Then: |
|
|
|
|
|
|
|
|
(a) 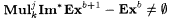 . . |
|
|
|
|
|
|
|
|
(b) 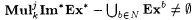 . . |
|
|
|
|
|
|
|
|
8.48 Proposition Let b, j, 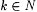 be such that be such that 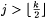 . Then, . Then, 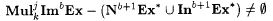 |
|
|
|
|
|
|
|
|
Proposition 8.47(a), for example, says that there are collections of functions for which a program that makes up to (b + l) errors can be identified from multiple texts, a majority of which are *-imperfect, but for which a program that makes only up to b errors cannot be identified from a single accurate text. Propositions 8.47 and 8.48 yield a number of hierarchies. We note one of them in the next corollary, which implies that strictly larger classes of functions can be identified from multiple inaccurate texts, a majority of which are *-imperfect, by allowing extra anomalies in the final program. |
|
|
|
|
|
|
|
|
8.49 CorollaryLet j, 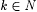 be such that be such that 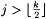 . Then, . Then, 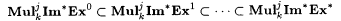 . . |
|
|
|
|
|
|
|
|
We now consider situations in which a scientist pays a price for learning from multiple inaccurate texts instead of learning from a single inaccurate text. We restrict ourselves to the case of noisy data delivered on three inaccurate texts, at least two of which are |
|
|
|
|