|
|
|
|
|
|
(a.1) M NaExb-identifies f (written: 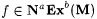 just in case for all a-noisy texts G for f, just in case for all a-noisy texts G for f, 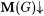 and j M(G) =b f. and j M(G) =b f. |
|
|
|
|
|
|
|
|
(a.2) 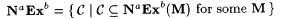 . . |
|
|
|
|
|
|
|
|
(b.1) M InaExb-identifies f (written: 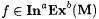 just in case for all a-incomplete texts G for f, just in case for all a-incomplete texts G for f, 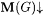 and j M(G) =b f. and j M(G) =b f. |
|
|
|
|
|
|
|
|
(b.2) 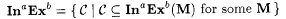 . . |
|
|
|
|
|
|
|
|
(c.1) M ImaExb-identifies f (written: 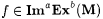 ) just in case for all a-imperfect texts G for f, ) just in case for all a-imperfect texts G for f, 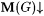 and j M(G) =b f. and j M(G) =b f. |
|
|
|
|
|
|
|
|
(c.2) 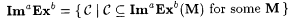 . . |
|
|
|
|
|
|
|
|
As an example of a collection of functions whose identifiability is not affected by the presence of a finite number of inaccuracies in texts, consider the class 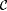 of constant functions, i.e., of constant functions, i.e., 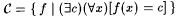 . It is easy to construct a scientist that identifies . It is easy to construct a scientist that identifies 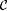 on *-noisy texts, *-incomplete texts, and *-imperfect texts. On the other hand, no scientist identifies on *-noisy texts, *-incomplete texts, and *-imperfect texts. On the other hand, no scientist identifies 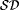 , the collection of self-describing functions1, from 1-incomplete texts. , the collection of self-describing functions1, from 1-incomplete texts. |
|
|
|
|
|
|
|
|
The basic idea of the foregoing Definitions 8.6 and 8.9 is easily extended to other criteria of learning introduced in Chapter 6. For example, consider the language learning criterion 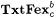 , according to which a scientist M is successful on a language L just in case, given any text for L, M converges to a finite set of indexes D such that , according to which a scientist M is successful on a language L just in case, given any text for L, M converges to a finite set of indexes D such that 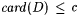 and each index in D is for some b-variant of L. An a-noisy-text version of and each index in D is for some b-variant of L. An a-noisy-text version of  is defined by requiring the scientist to is defined by requiring the scientist to 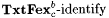 a language on any a-noisy text. The resulting paradigm is named a language on any a-noisy text. The resulting paradigm is named 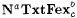 . With this background, the reader may easily formulate the exact definitions of the following paradigms for language identification: . With this background, the reader may easily formulate the exact definitions of the following paradigms for language identification: 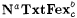 , , 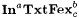 , , 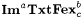 , NaTxtBcb, InaTxtBcb, and ImaTxtBcb. , NaTxtBcb, InaTxtBcb, and ImaTxtBcb. |
|
|
|
|
|
|
|
|
Several criteria of function identification studied in Chapter 6 may also be adapted to the present context. In particular, we shall focus on NaBcb, InaBcb, and ImaBcb in what follows. |
|
|
|
|
|
|
|
|
The present section considers the tradeoff between inaccuracy in the available data versus leniency in the learning criterion. In particular, we investigate the effect of allowing |
|
|
|
 |
|
|
|
|
1Recall from Chapter 4 (Definition 4.24) that 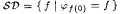 . . |
|
|
|
|